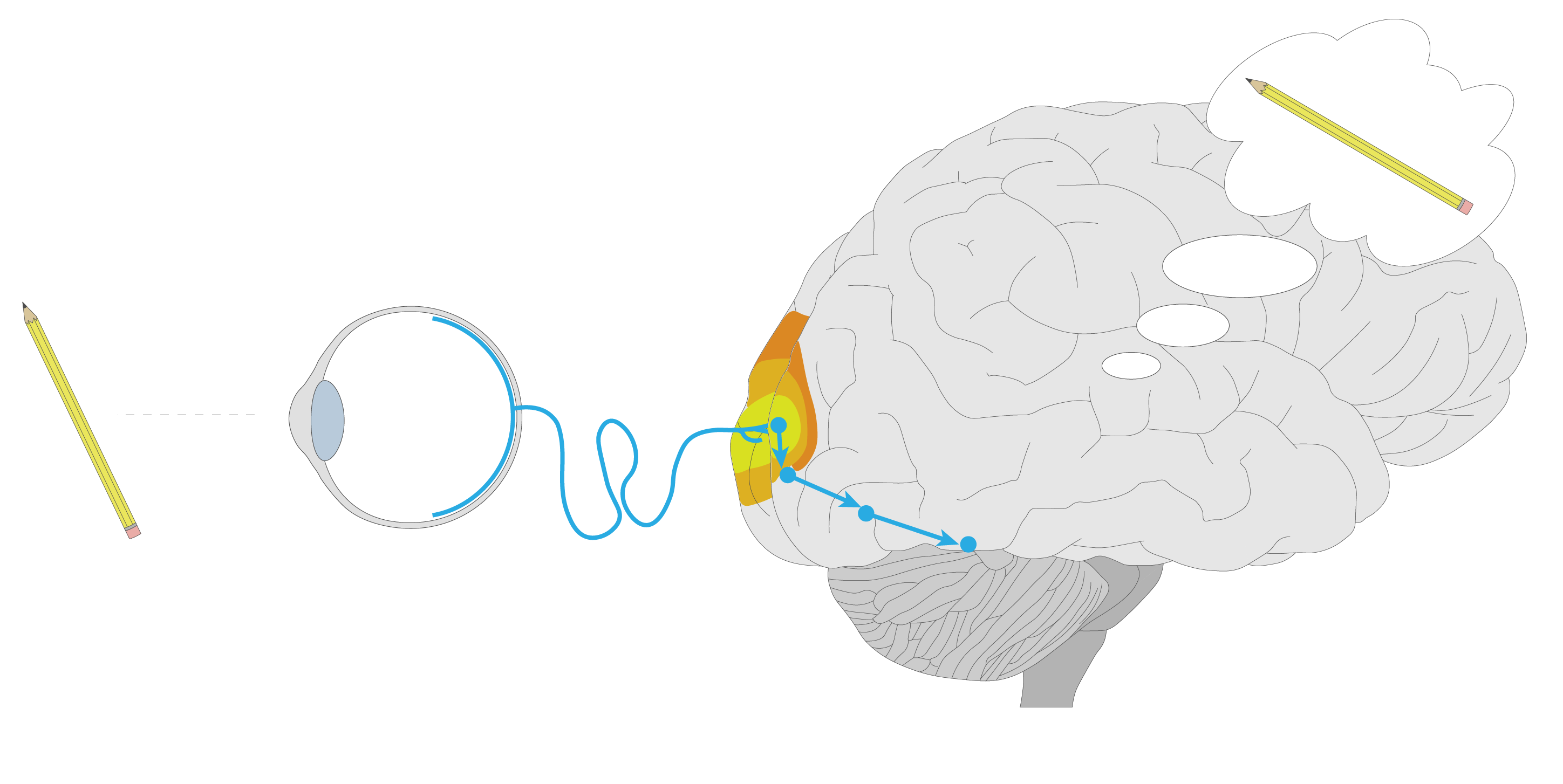
So when we see something in front of us, like a pencil, how exactly does the brain understand that yep, that’s a pencil?
Like, what is the detailed sequence of steps that happens? The eyes presumably convert the light to neural signals (how?), then these get sent to the brain (where?), and then the brain does… what?
I’ve been reading through a bunch of neuroscience textbooks and papers for the past six months, and I think I’m at the point where I’ve now got the whole picture.
So here are the core pieces of this picture, with a lot of details omitted to fit it into a short blog post.
Let’s start with the input.
What exactly do the eyes do?
The main output of the eyes are the neurons called ganglion cells that live in the thin layer of tissue at the back of the eye. To grossly oversimplify, these ganglion cells transmit the brightness of each pixel of the picture that’s projected onto the back of the eye, though the reality is much more complex.
To transmit this information, the neurons use spikes of voltage – that’s when the voltage between the inside and the outside of the cell suddenly rises from somewhere around -60 mV to around 0 mV and falls back down over the course of about a millisecond.
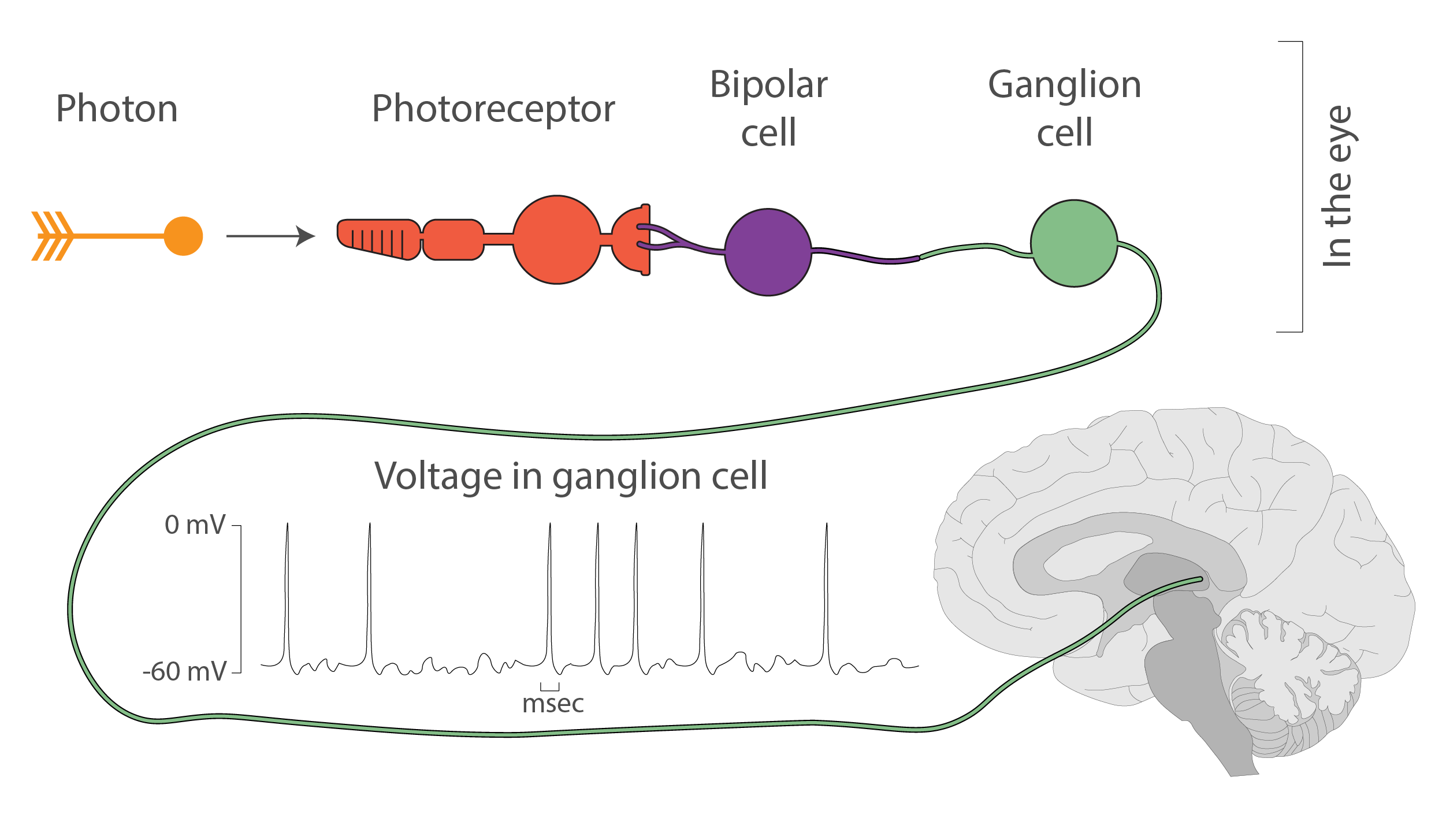
In the eyes, these spikes are caused by light-sensitive proteins called opsins that live in cells of another type, the photoreceptors. When photons hit the photoreceptor cells, the opsins in these cells absorb the photons and slightly change their structure, which causes a rapid cascade of chemical reactions across a few cells. At the end of this series of reactions, the ganglion cells let in some positively charged ions, raise their internal voltage, and start a spike.
(I’ve written more about how the ions cause spikes in another post)
![]()
The whole system is set up to handle different volumes of light: the more light is shining on the photoreceptors, the more spikes are produced by the ganglion cells.
So, to grossly oversimplify even more, more light => more spikes in the ganglion cells.
And now what?
Where do the signals go?
The ganglion cells live at the back of the eyes, but they have long output extensions (axons) that run from the eye, through the optic nerve, and right into the center of the brain. That’s where the thalamus – the brain’s main switchboard – is located.
In an adult human, that’s about 10 cm or 4 in of length, and that’s far from the record for the length of a neuron. The spikes travel along the full length.
One of the interesting things that happen along the way is that the optic nerves cross at about the half-way mark, and the neurons from the left half of each eye end up traveling to the left half of the brain, while the neurons from the right half of each eye go to the right.
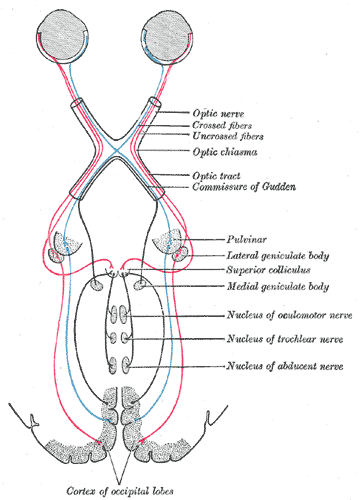
This way, each hemisphere of the brain will be able to construct a stereo picture of each half of the visual field.
From the thalamus, a new set of neurons picks up the same information and forwards it to the back of the brain - the occipital lobe - where the brain will do its magic.
And the brain does… what?
In the brain, visual processing is done through a sequence of visual cortex areas - V1, V2, V3, etc, each of which extracts progressively more complex features from the original signal.
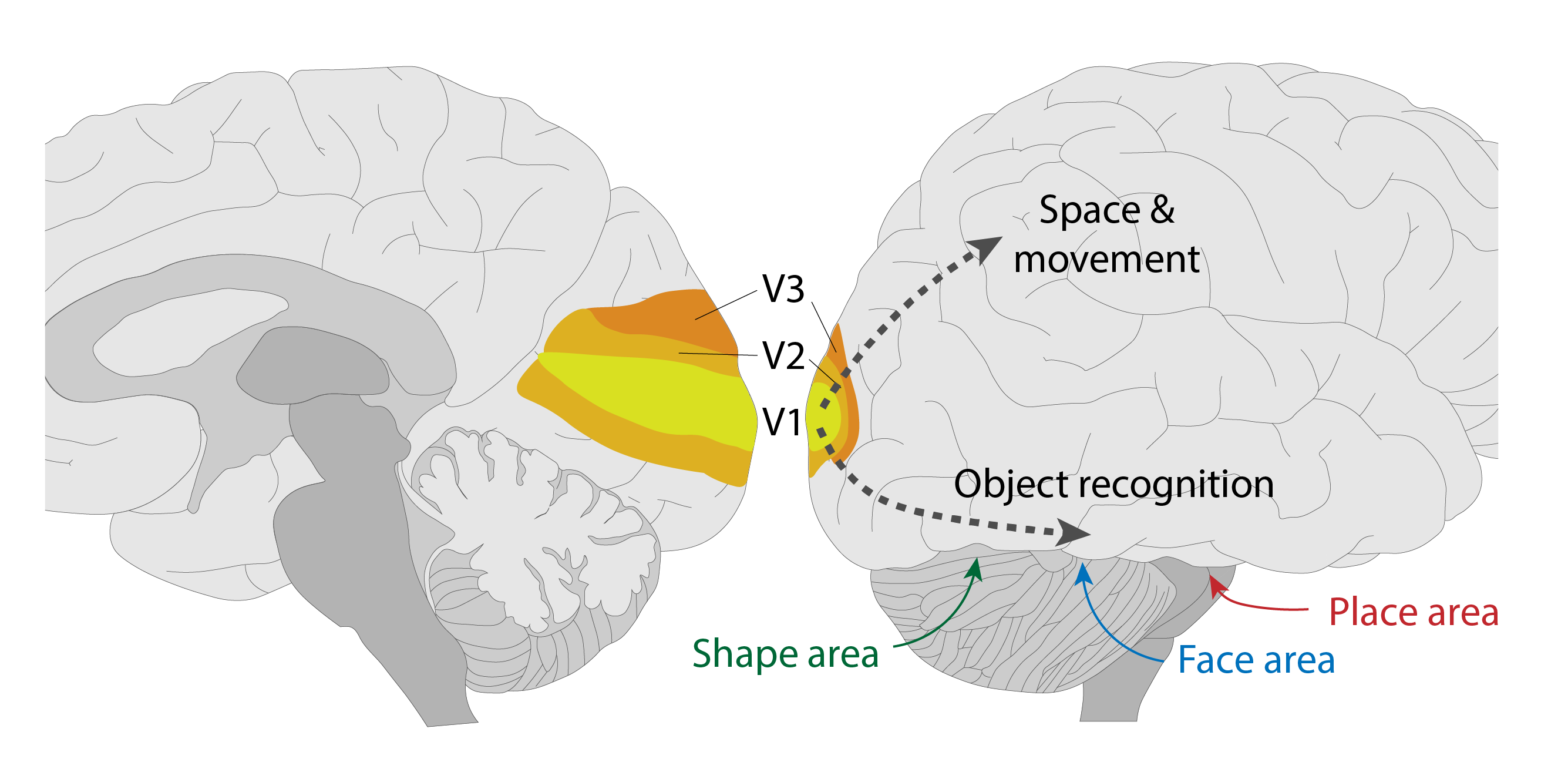
The first one of these, V1, is located right at the back of the brain; it represents nearly pixel-for-pixel what the eye sees - that is, the neighboring neurons in V1 represent neighboring points on the image.
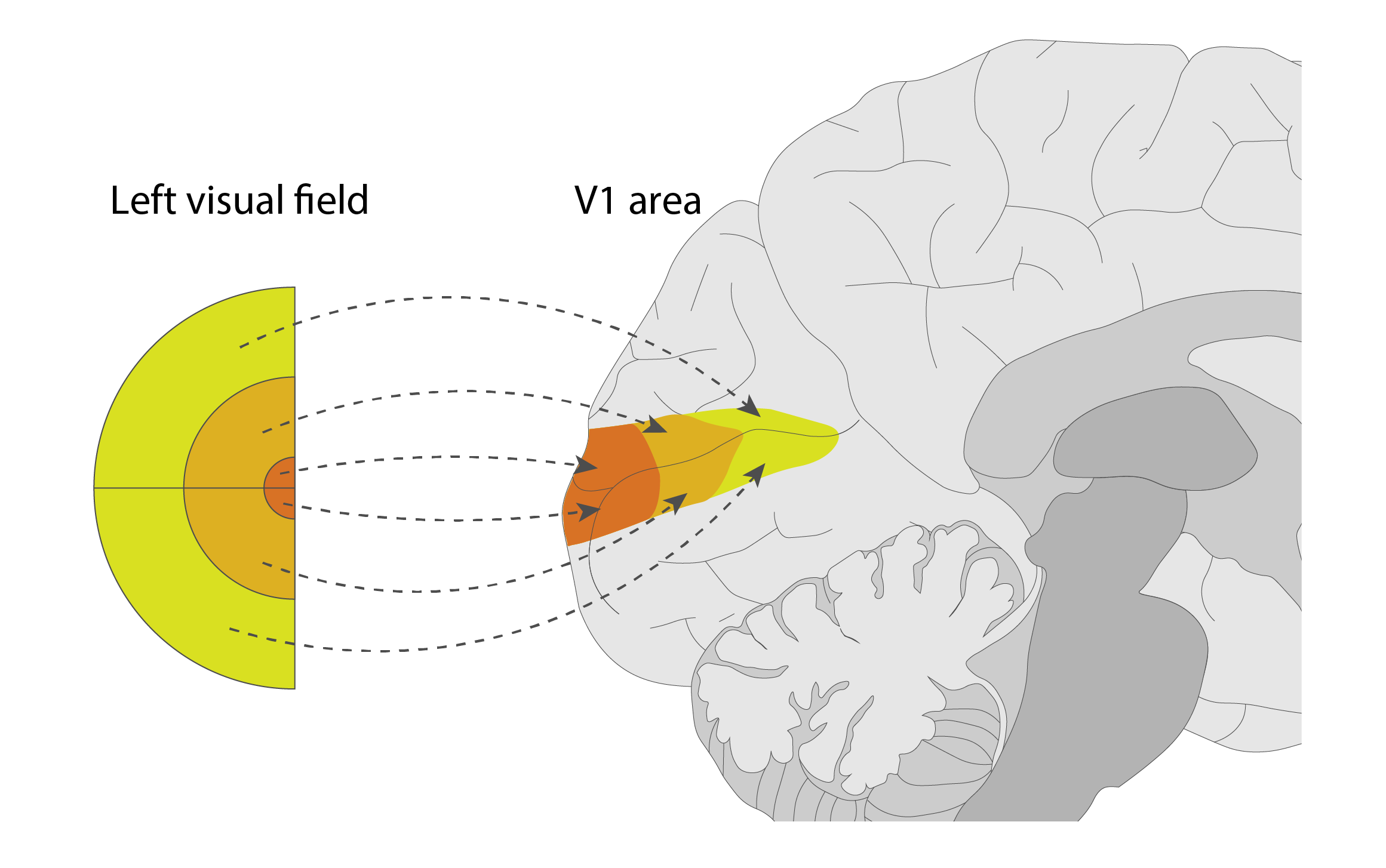
In V1, a series of neural connections detect basic features like edges, colors, directions, or motion in each patch of the visual field. If the neurons responsible for detecting a specific feature detect it, they fire a series of spikes, letting the downstream areas know what they found.
The downstream areas - V2, V3, etc. - extract progressively more and more complex features over larger and larger areas.
If you’re familiar with Convolutional Neural Networks (if you’re not, here’s a good explainer), that’s pretty much exactly what’s going on here.
Early on, the processing path splits into two branches: the bottom one that’s focused on recognizing objects, and the top one that’s focused on building a mental picture of space and motion.
At the end of the bottom branch are the areas that recognize faces, places, or objects, including the pencil that we started with.
Here, if the final collection of features extracted along the way add up to a specific known object, a collection of neurons that are associated with that object fires spikes to other areas of the brain, triggering appropriate emotions, thoughts, memories, and other associations that we may need at the moment.