It’s been almost four months since we’ve migrated to AWS Elastic Kubernetes Service at HOOPP‘s 90-person Investment Solutions Group, and we’re starting to get a sense for what it’s like running on it.
While we ultimately liked it, right from the first interaction it became apparent that Kubernetes was not a complete platform, just a good backbone for a platform. If we wanted a group of 90 developers, business analysts, and product owners to work comfortably with it day-to-day, we needed to deal with configuration/operation complexities, platform quirks, and some gaps in tooling.
To deal with that, we did what I’ve observed as a trend: we put our own platform layer on top of Kubernetes. This post goes into that layer.
There are three areas where we had to make additional improvements:
- Interface between the developers and Kubernetes
- Operations and maintenance
- Auxiliary tooling, like logging, monitoring, and dashboards.
Still, we liked Kubernetes
The migration wasn’t cheap (for us). It took five months from “let’s try it out” to post-migration cleanup, with two to nine people working on it depending on the time. But ultimately it was worth it.
Compared to our last platform, AWS Elastic Beanstalk, on Kubernetes we got:
- Quick, painless deployments that needed less attention.
- Less distractions for the delivery teams, who could now iterate faster on their features.
- Stupidly easy high availability, including 100% uptime during deployments and self-healing after random crashes of service instances.
- Helm charts. These are third-party “packages” of functionality that you can install on your Kubernetes cluster with a single command. We discovered these after starting work on the migration, and they made our lives much simpler. For example, Splunk (Helm chart), ALB Ingress Controller (Helm instructions) and other components and tools were installed this way.
- Lower costs because we could pack more containers on individual EC2 instances.
- Easier disaster recovery. With declarative deployments and Helm charts, we’ll spend a lot less time redeploying a new, fully working production environment.
- Many convenience features that made the overall setup easier, including cluster-internal DNS for service discovery and simpler provisioning of AWS load balancers.
Overall, Kubernetes now feels like a solid, stable backbone of our infrastructure. Aside from some initial move-in pains, it is now giving us minimal trouble, and it feels like we won’t have to think much about for the next five years.
A side note: pension plan investment management is not the kind of business that requires scaling to a large number of instances. Our problem was making the infrastructure work effectively for a dozen or so teams, and making horizontal scalability not a concern in the few cases where we needed it. I’ve had people wonder whether Kubernetes was needlessly complex for this kind of organization. With hindsight, and having experienced other platforms and infrastructures, the answer is definitely “not too complex”.
…But Kubernetes wasn’t enough.
Though it was a good platform, but if we had made our delivery teams interact with Kubernetes directly, their lives would have become a lot more complicated.
1. Developer interactions with Kubernetes
The config files
After turning all the knobs and dials, our typical Kubernetes config files ended up being about 100 lines long. Each service needed its own config file, as there were some per-service differences between the files. If each team has 4-10 services, that’s a lot of config files. Easy to make a subtle mistake and spend days troubleshooting; hard to make wholesale changes to all of them.
Instead of large config files, wouldn’t it be nice if each service had a shorter manifest file that explained how it’s different from other services, like this:
1 | name: my-service |
We ended up building exactly that. Each service got a service.yml file in its root folder; our build+release tooling interpreted it, generated an appropriate dockerfile and Kubernetes config.yml, and used the right settings in various intermediate commands, like the command to create a container repository in AWS Elastic Container Registry.
The initial work to implement this was around two people working over four weeks, and included design/development, updating Azure Pipelines, educating the teams, and adding service.yml to each existing service. We then spent about as much time on updates and cleanup.
In case you’re familiar with Cloud Foundry, the service.yml file was heavily inspired by its manifest files. We didn’t go with Cloud Foundry because the providers we looked at were either too expensive (Pivotal) or were buggy and had questionable customer service (IBM Bluemix).
We did look at the options on the market to solve the problem. In each case, the time to evaluate, implement, and deal with the quirks would have been longer than to build our own, and that’s before adding time for the vendor assessment and contract negotiations.
Other interfaces to Kubernetes
From our previous experience, we found that:
Product Owners liked to control the time of deployment to UAT or production. We already had existing Azure Pipelines deployments, and the product owners were comfortable using them, so we made sure to keep the experience the same for them when switching over to Kubernetes.
Developers:
The developers’ preferences varied from team to team. Some teams liked continuous deployments to their test environments, and some did not. Some teams had several test environments, and some had only one. The solution to most of these preferences was Azure Pipelines as well.
We did, however, run into a problem when someone wanted to restart a service. One of the Kubernetes quirks is lack of an explicit rolling restart ability, i.e. the ability to restart all instances in batches, while keeping at some of them online. This is an explicit design decision that will not be fixed. There is still a way to force a rolling restart to happen, but it’s rather roundabout.
After some discussions, it turned out that our developers typicallty restarted services because of application configuration changes. When the config changed in the central configuration Git repository, they needed the service restarted. So we built an Azure Pipelines release that restarted all services affected by the configuration change and reported the event in Slack:
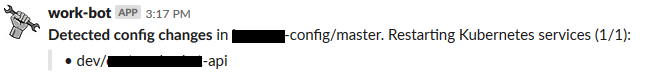
Sometimes the developers did need to interact directly with Kubernetes, and so everyone got kubectl installed on their machines, and got access to the Kubernetes dashboard.
Service dashboard
One of the gaps that we still have is a good service dashboard. Kubernetes does have a dashboard, but it presents a Kubernetes view of the system: separate lists of deployments, pods, namespaces, other Kubernetes objects. To see the complete state of your service, you’d have to browse across multiple objects on multiple screens.
The developers, on the other hand, thought of a service as a single line on the dashboard that combined all underlying Kubernetes information from the pods, deployments, and ingresses. It would have maybe the service name, a state indicator (healty/unhealthy/deploying), a few actions (e.g. “restart”), and links to relevant resources (e.g. logs).
This is still on our wish list, and we may build one if we don’t find one in the next few months.
2. Maintenance and operations
This is the area where Kubernetes made us do more work than Elastic Beanstalk, our previous platform.
Once you have yor cluster, you’ll have to take care of a few operational problems:
Cluster auto-scaling, i.e. expanding or reducing the number of nodes in the cluster in proportion to the load. This did not come out of the box and we had to build it using AWS auto scaling groups.
Cluster upgrades, including the Kubernetes version, the kubelet agents, and node EC2 images. Some components have to have versions that are in sync with some other Kubernetes components. Any upgrades will need to be done across all clusters you have, without disrupting production or integration testing. The good news is that Kubernetes will help you out with moving the replicas from one node to another and keeping some replicas alive. But we still had to orchestrate the whole upgrade process ourselves and fine-tune it to make sure that it causes minimum disruption.
Container image upgrades. Sometimes you’d want to swap out the base image for the containers without changing the code that’s running on them. In cases of security issues, you’d want to do this for all containers on the cluster, ideally within a day. Again, without disrupting production or integration testing.
Be prepared for service instances getting killed by any of the above processes at any time. If your teams are not used to programming for random disruptions, they now will have no choice because the service instances will get taken offline at inconvenient times.
None of the above were rare one-off processes; they occured regularly, and you have to be ready for it. For us, the work on this involved not just building CloudFormation templates and back-end processes, but also updating our service framework, working with the teams to educate them about the best architectural decisions for the platform, and helping implement some architectural changes.
Automation of some of these processes came in very handy when we were fine-tuning the EC2 instance types used as the cluster nodes. This allowed us to try out several instance types and eventually settle on the ones that had the right mix of CPU, memory, and cost.
We still have not automated container image swaps, in part because it would have require reworking parts of our build+release pipelines and retaining more build artifacts for longer time than we would like.
3. Additional tooling
The other major functionality that we wanted out of the platform was logs, monitoring, alerts, security scans. As features, these were either barely present in Kubernetes (log viewing), didn’t work well out of the box (the dashboard), or wasn’t there at all (the rest).
Fortunately, with Helm charts it was easy to set up the tools we already had in-house.
Logging: we added Splunk, which we already using elsewhere. The Helm chart install was straightforward, except for a few minor surprises like incorrect splitting of individual events and incorrect timestamps. Some of it we fixed; some was not worth the trouble.
Monitoring and alerting: added DataDog. Kubernetes and AWS feed some useful metrics into DataDog, though some weren’t immediately obvious.
Kubernetes Dashboard: has nice features and is a good UI alternative to the
kubectlcommand line tool. The biggest issue was that we wanted it to integrate with either AWS access management or with the corporate SAML. It turned out harder than expected; we eventually did it months after the Kubernetes migration. As mentioned before, the dashboard was great for Kubernetes operations, but not quite what the delivery teams needed.Container security scanning was not necessarily a Kubernetes problem, but it was something new that we had to deal with. After reviewing the options, we went with Anchore scan, which we also installed as using a Helm chart.
Final words
Kubernetes is a very nice tech, and a great piece of an overall solution. But for now it needs to be combined with custom in-house and third-party tools, otherwise it won’t help speed up the development or operations.
I would not be surprised if in five to ten years we will see emergence of a platform that will offer a complete end-to-end service management experience that would combine Kubernetes, Istio, and various other components, just like Kubernetes emerged as an end-to-end solution to the container orchestration problem.